
¡Hola gente! Año nuevo, vida nueva y, finalmente, viejos sueños y metas están saliendo del papel. Para mi primer blog, a principios de 2022, elegí hablar sobre Operador de Kubernetes del Oracle Database, también conocido como OraOperator.
Este artículo también proporciona una breve introducción al Operador de Kubernetes, y no podía dejar de lado la arquitectura nativa de la Cloud – la base de todo.
Introducción sencilla al Operador de Kubernetes
¿Por qué escribir un Operador de Kubernetes? ¿Qué es un Operador y por qué es vital que el sistema experto funcione sobre Kubernetes, casi una simbiosis? Trataré de explicar en esta sencilla introducción a Operator.
Los Principios de Diseño Nativo de la Cloud
Primero, como línea base, una Arquitectura Nativa de la Cloud es un conjunto de principios o prácticas enfocadas en optimizar los sistemas para los recursos únicos de la Cloud, buscando lograr una mayor agilidad y mantenibilidad de las aplicaciones, resiliencia, escalabilidad y consumo eficiente de recursos, para enumerar algunos de los principales objetivos. Podemos resumir estos principios a través del esquema presentado en la siguiente figura.
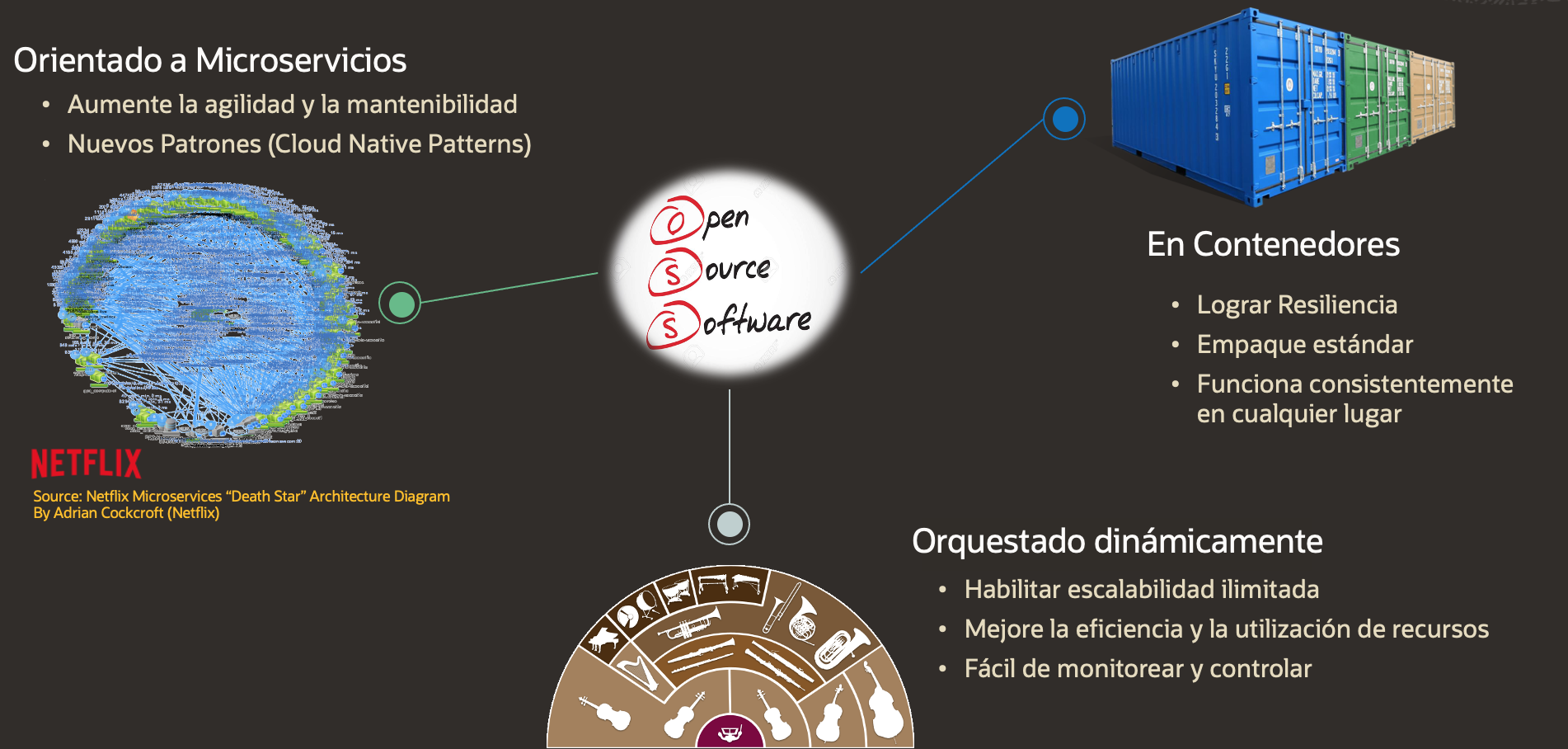
Estos principios de diseño sugieren la adopción de una arquitectura de microservicios, dividiendo las aplicaciones con un enfoque en aumentar su agilidad y mantenibilidad.
El uso de contenedores para empaquetar y distribuir los microservicios proporciona una infraestructura inmutable que busca lograr la resiliencia de la aplicación; Y organiza dinámicamente estos contenedores con un enfoque en el consumo eficiente de recursos al tiempo que permite la elasticidad.
El proyecto Kubernetes es el motor a cargo de orquestar dinámicamente los contenedores, aprovechando las capacidades de los contenedores para administrar todo su ciclo de vida y brindando capacidades como la recuperación automática y la reconciliación.
Pero los contenedores son efímeros por las mejores prácticas, lo que significa que si mueren, no hay un estado guardado, o mejor, pierdes todo lo que hay dentro. Este enfoque sin estado sigue el sexto factor de la metodología de aplicación de 12 factores, que recomienda “ejecutar la aplicación como uno o más procesos sin estado”.
Y, además, Kubernetes no fue diseñado para gestionar el estado de forma predeterminada. Por lo tanto, ¿cómo podemos aprovechar la orquestación dinámica y la creación de contenedores que provienen de Kubernetes para ejecutar almacenes de datos altamente distribuidos, como una base de datos? ¿Cómo podemos “adaptar” nuestra aplicación con estado para usar Kubernetes y al mismo tiempo mantener el estado, aplicar la replicación de datos, la automatización de conmutación por error (nuevamente administrar el estado), etc.?
Ok, es posible hacerlo a mano, lo que significa escribir código para superar el entorno sin estado y proporcionar lo que necesitamos, pero para ser honesto, es una tarea propensa a errores y herculeana. Ahí es donde dejas que el Operador trabaje para ti.
El Operador de Kubernetes
Usando una idea muy presente en estos días, “Todo como un código”, un patrón Operador es una forma de poner al operador del sistema sujeto, nuestro conocido sysadmin o dba, “como un código”. El Operador tiene 3 componentes, un proceso ejecutor especializado u orientado al dominio – el Controlador – que se sienta en el ciclo, observando una aplicación o una infraestructura, para asegurar que sus estados durante la ejecución – el estado actual – son los deseados, y que están documentados por el estado declarado en un lenguaje específico de dominio.
Específicamente para Kubernetes, tenemos una descripción bastante concisa de Jimmy Zelinskie que dice que “Un operador es un controlador de Kubernetes que entiende 2 dominios: Kubernetes y algo más. La combinación del conocimiento de ambos dominios puede automatizar tareas que normalmente requieren un operador humano que comprenda ambos dominios”.
El siguiente diagrama explica este estado de observabilidad del operador para mantener el estado deseado en función de la comparación de los estados declarados y actuales.
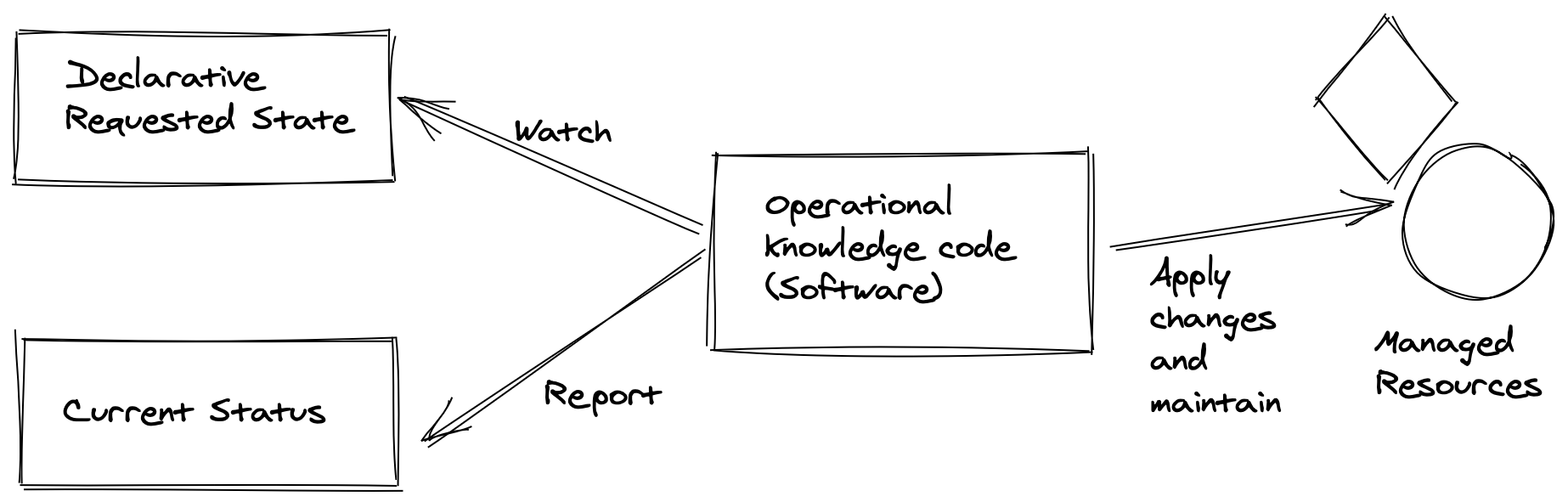
Entonces, cuando tenemos una aplicación o infraestructura con estado para implementar y administrar, y decidimos crear un operador, creamos un componente de controlador de Kubernetes con capacidades para comprender e interactuar con el dominio de Kubernetes y sus API y, al mismo tiempo, comprender que dominio especializado y operar para proporcionar administración con estado, automatización de recuperación de bloqueo sin romper la consistencia de la aplicación, así como funciones administrativas como copia de seguridad/restauración y muchas otras tareas operativas cruciales, todo “como código”.
Además del controlador, el operador también incluye recursos personalizados y definiciones de recursos personalizados (CRD). El estado deseado de la aplicación se encapsula en uno o más CRD utilizando el lenguaje específico del dominio, y el Controlador tiene el conocimiento operativo para manejar estas definiciones y llevar los objetos de la aplicación al estado deseado.
Para obtener más detalles sobre el Operador de Kubernetes, recomiendo CNCF Operator White Paper.
El Operador de Kubernetes del Oracle Database (también conocido como OraOperator)
No tengo miedo de decir que Kubernetes es el orquestador de la infraestructura de la Cloud, proporcionando el mecanismo dinámico para manejar los Contenedores, brindando resiliencia, autorreparación, una especie de elasticidad operativa. Y ejecutar y aprovechar esta fantástica tecnología es clave para el éxito en las implementaciones nativas de la Cloud.
Es fantástico que Oracle haya decidido hacer que Oracle Database sea nativo de Kubernetes, lo que hace que la base de datos más crítica y adoptada del mundo sea operable y observable por un componente esencial de la infraestructura nativa de la Cloud.
Oracle Database es una infraestructura con estado y requiere funciones operativas de nivel empresarial, como copia de seguridad/restauración, resiliencia, automatización de recuperación ante desastres, etc. Entonces, para que sea factible ejecutar Oracle Database en Kubernetes, Oracle ha puesto a disposición el Operador de Kubernetes del Oracle Database [OraOperator], que sigue el patrón Operator. Desarrollar la integración entre la infraestructura de Kubernetes y la infraestructura de Oracle Database, lo que les permite trabajar juntos para ofrecer una de las plataformas de gestión de datos nativos en la Cloud más potentes.
El proyecto OraOperator implementó funciones de Kubernetes, como controladores y definiciones de recursos personalizadas, para automatizar algunas tareas de administración del ciclo de vida de Oracle Database. Por ejemplo, a continuación se muestra el código CRD para Sharding Database.
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.6.1
creationTimestamp: null
name: shardingdatabases.database.oracle.com
spec:
group: database.oracle.com
names:
kind: ShardingDatabase
listKind: ShardingDatabaseList
plural: shardingdatabases
singular: shardingdatabase
scope: Namespaced
versions:
- name: v1alpha1
schema:
openAPIV3Schema:
description: ShardingDatabase is the Schema for the shardingdatabases API
.....
Configuración admitida por el OraOperator
La versión actual (v0.1.0) también admite tareas de administración fuera del clúster de Kubernetes, lo que ayuda a los ingenieros de confiabilidad de bases de datos (DBRE) con su trabajo diario mediante los comandos de Kubernetes – kubectl –. Esto significa que puede operar Oracle Autonomous Database (ADB) usando OraOperator.
La siguiente lista resume qué configuración y operaciones de la base de datos de Oracle son compatibles:
- fuera-cluster-K8s
- Configuración la base de datos: Autonomous DB 1
- Operaciones:
aprovisionamiento, vinculación, inicio, detención, finalización (soft/hard), escalado (up/down)
- Operaciones:
- Configuración la base de datos: Autonomous DB 1
- en-cluster-K8s
- Configuración la base de datos: Single Instance databases (SIDB) 2
- Operaciones:
aprovisionamiento, copia, aplicación de patches (en el sitio/fuera del sitio), actualización de los parámetros de inicialización de la base de datos, actualización de la configuración de la base de datos (Flashback, Archive), Oracle Enterprise Manager (EM) Express (una consola de observación básica)
- Operaciones:
- Configuración la base de datos: Containerized Sharded databases (SHARDED)
- Operaciones:
aprovisionar/implementar base de datos fragmentada y topología fragmentada, agregar un nuevo fragmento, eliminar un fragmento existente
- Operaciones:
- Configuración la base de datos: Single Instance databases (SIDB) 2
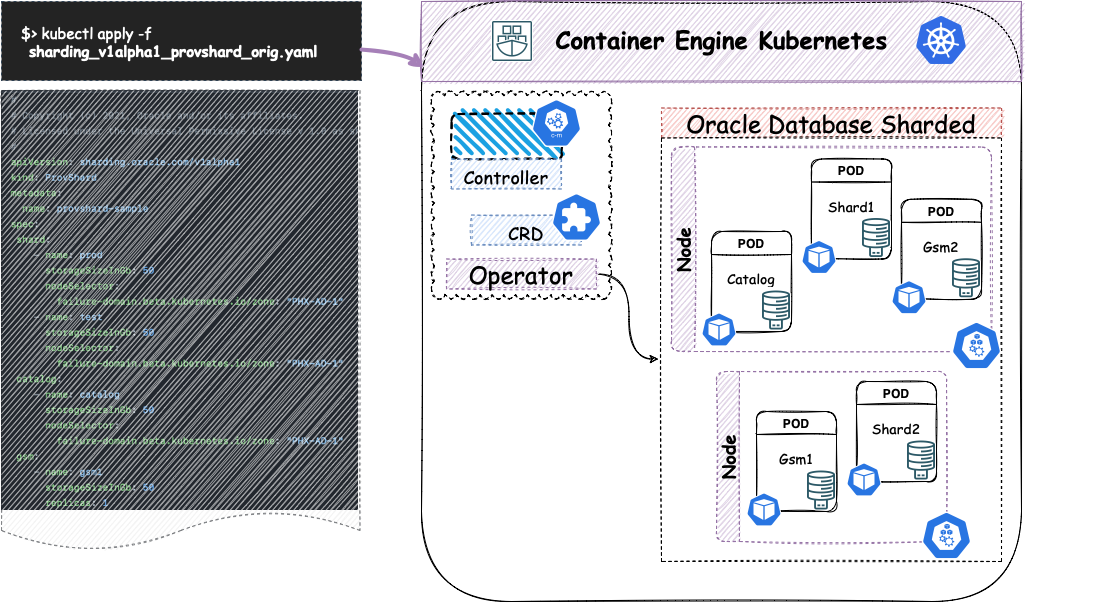
Una descripción general del Operador para una base de datos fragmentada (Sharded)
Como ejemplo de uso, el siguiente diagrama muestra la adopción de OraOperator para implementar la opción Oracle Database Fragmentado (Sharded). Después de instalar Operator dentro de OKE 3, instalaremos nuestra base de datos fragmentada con dos contenedores para instancias de bases de datos fragmentadas, dos contenedores con GMS y una instancia de Catálogo.
Revisión de la versión
La versión 0.1.0 viene con muchas características valiosas para nosotros, los desarrolladores, así como para los BDREs. Funciona con la base de datos Oracle de instancia única (SIDB) y se puede implementar en nuestra computadora portátil usando Minikude, por ejemplo. La próxima versión aumentará la cantidad de distribuciones de Kubernetes de otros proveedores que se certificarán, así como las opciones de configuración de la base de datos, como las bases de datos locales (CDB/PDB).
Además, la versión actual de OraOperator (v0.1.0) debe usarse solo para desarrollo y prueba. NO UTILIZAR EN PRODUCCIÓN.
Referencias
Algunas referencias para continuar el estudio:
- Oracle Database Operator for Kubernetes GitHub
- Material de mi amigo y también líder del proyecto Kuassi Mensah (Director de Gestión de Producto para el acceso de Java a Oracle DB)
¿Que sigue?
Sí, este artículo es un piloto de una serie sobre Oracle Database Kubernetes Operator, y el próximo episodio será sobre “Presentación de OraOperator para bases de datos de instancia única”.
Agradecimientos
- Contribuyentes - Pablo Silberkasten, Senior Manager, Software Engineering at Oracle
Oracle Autonomous Database en Oracle Cloud Infrastructure (OCI) compartida, también conocida como ADB-S ↩︎
Contenedorizado Single Instance databases (SIDB) ↩︎
Oracle Container Engine for Kubernetes (OKE) es un servicio de Kubernetes administrado que se ofrece en Oracle Cloud Infrastructure. ↩︎